16 February 2025
Moving Targets in AI
In the face of rapid changes in the field of AI, Programme Director Suraj Bramhavar reflects on evolving benchmarks within ARIA's Scaling Compute programme.

The thesis that started the Scaling Compute programme and continues to be affirmed by developments in the field of AI is that there is a fundamental asymmetry between our demand for more compute and its supply. Technologies that enable increased compute supply will have major economic, geopolitical, and societal implications: We need research and inventions that help us rethink both our existing hardware infrastructure and training paradigms.
This programme was set up to address these challenges, with the overarching goals of reducing the cost to train large-scale AI models by 1000x, diversifying the semiconductor supply chain, and providing entirely new vectors for continued computing progress.
Since we set the programme targets (almost a year ago!), a lot has changed in the landscape of AI. With work now underway across 12 teams from across industry and academia, we recently convened these teams to share progress, but also to ask some fundamental questions: Given the commercial incentives in a fast-moving industry, how do we remain focused on ARIA’s goal to build technologies that are underserved relative to their impact AND that will be relevant on a decadal timescale? How do we know what to shoot for? We want to ensure that we maintain ambitious and relevant targets that can change the conversation about what is possible.
Two recent external events highlight this pace of change:
- OpenAI released its ‘chain-of-thought’ models, introducing an alternative scaling pathway to improve the power of modern AI models via repetitive inference (thus decreasing the importance of scaling pre-training).
- DeepSeek released a technical report demonstrating significant algorithmic innovations for training significantly larger models than the ‘large’ GPT3 model identified above, highlighting both the pace at which relevant workloads evolve AND the innovation speed of large AI labs.
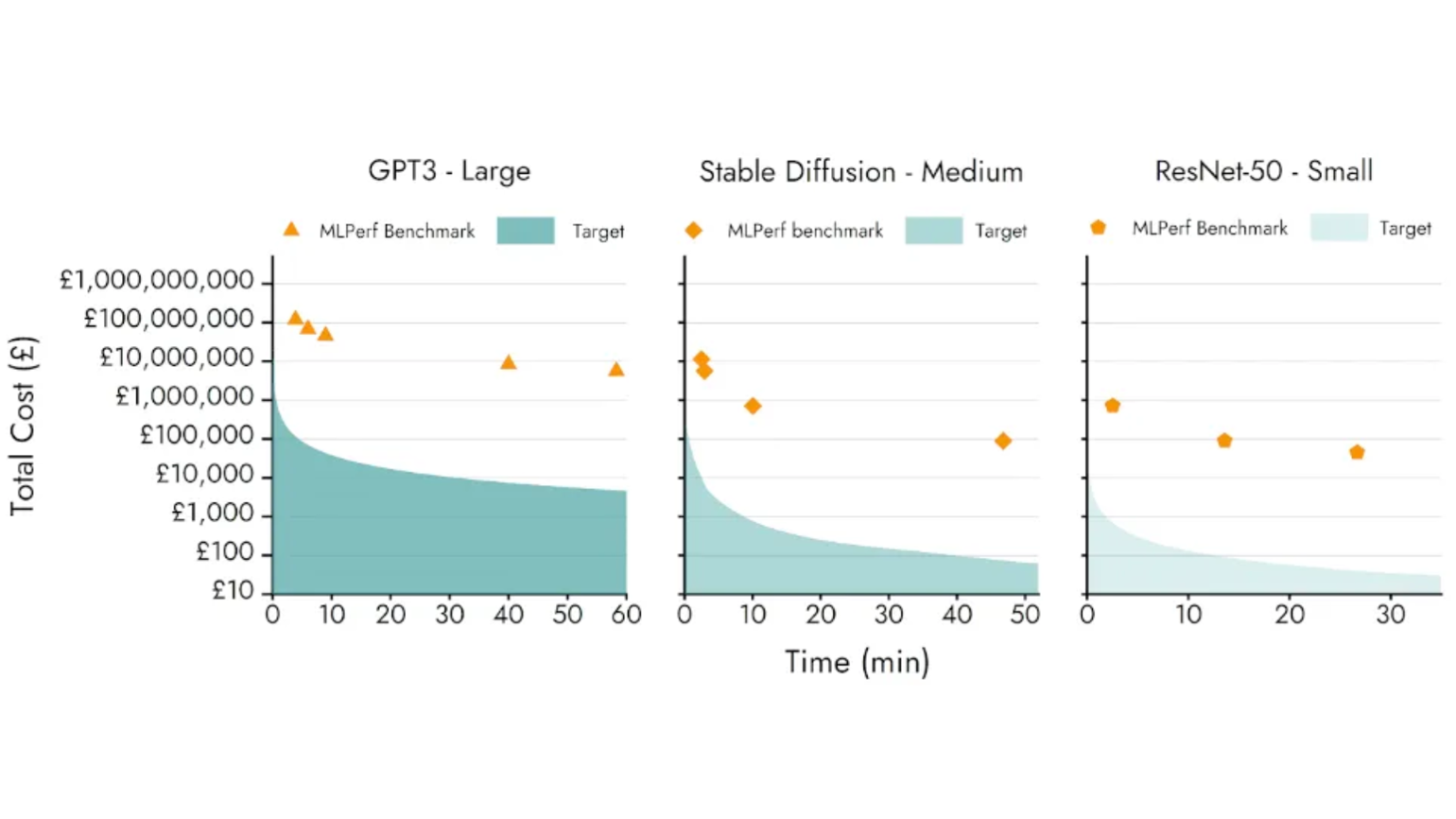
Figure 1. The current cost of training large AI models and the programme target for training workloads from MLPerf Benchmarks.
We focused our original programme targets on the cost to pre-train large-scale AI models (Figure 1), concluding that a significant amount of commercial interest was being paid to inference, and that much of the societal value stems from our ability to teach computers new capabilities. What we failed to specify (or predict) was that AI model training would take three valuable forms: pre-training, fine-tuning, and more recently, repetitive inference. Each form creates different demands on the underlying hardware.
It is clear now that attempting to predict which pathway will be most impactful in the years ahead may be difficult. We therefore put the following questions to our Creators:
- Should we replace our cost targets above with standard hardware-level targets as our north star (shown below)?
- Which models/workloads should we focus on?
- How can ARIA help?
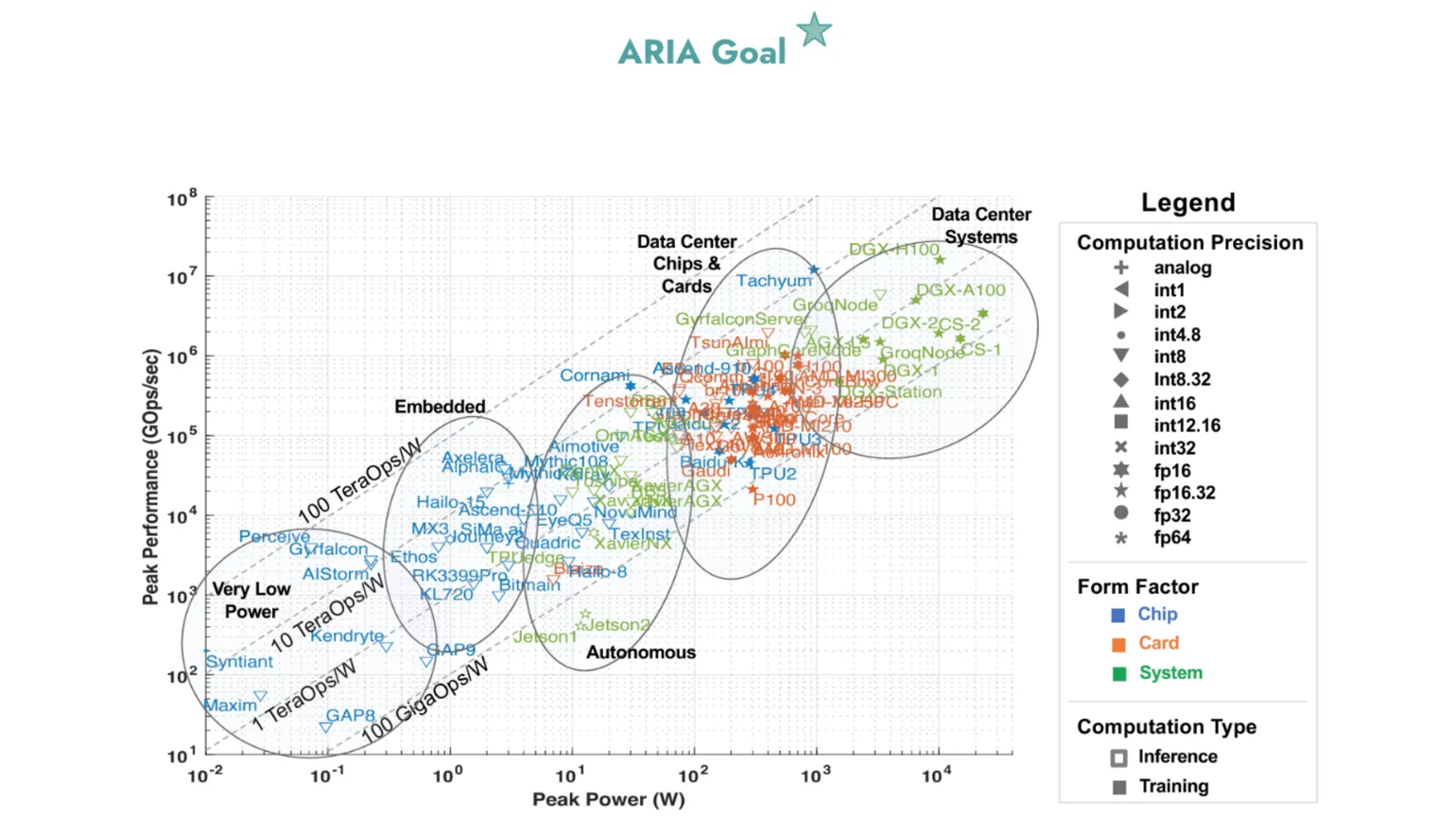
Source: https://arxiv.org/pdf/2310.09145
Figure 2. Plot showing performance of existing commercial AI accelerators. ARIA performance target shown above would result in a 1000x reduction in cost of AI hardware.
Community Response
When posed with the first question, our community overwhelmingly confirmed that the original focus on cost should remain the most appropriate goal (as opposed to specific hardware targets such as OPS/W). The shared rationale was that hardware performance specs inevitably miss many aspects of technological capability, and while technology translation is governed by many factors, the most significant single metric governing translation is cost (so long as all costs are properly accounted for).
The second question presents a more pressing challenge: how can the hardware research community keep pace with an incredibly nimble and extremely well-funded industry who ultimately serve as ‘customers’ for the hardware our Creators seek to build. Striking the right balance between technologies that are too risky for industry efforts yet relevant enough to maintain engagement is a perennial challenge.
The resulting discussion surfaced a few critical items as valuable additions to the Programme:
1. Thorough (and continuous) baseline cost accounting of existing commercial hardware.
2. Rapid assessment of relevant workloads and algorithmic optimisations being applied to this hardware.
The DeepSeek News
Much of this discussion comes on the heels of widely distributed reports from DeepSeek demonstrating impressive performance optimisations for training leading-edge AI models. While many popular media reports mischaracterise the magnitude of the achieved cost gains, this should not diminish the significance of what was achieved, and more importantly, it highlights the impact that can be realised by concentrated groups of world-class talent.
For the ARIA community, the news event serves as a reminder that algorithms research moves at breakneck pace, and that the hardware-level technologies being developed under this Programme should strive to either: a) compound atop the advances of this community, or b) catalyse the emergence of entirely new branches of algorithms research.
A New Funding Call For AI Hardware Benchmarking
It became exceedingly clear that, with all the commercial hype surrounding the space, there is a yearning for rapidly updated sources of ground-truth in a world where the ground is continuously shifting beneath our feet. In order to demonstrate technologies that blow past existing goalposts, we need to make sure we know where these goalposts actually are, and track them as they move.
A direct action taken from this discussion is that ARIA will onboard a team to provide this service. Existing benchmarking frameworks such as MLPerf will serve as a foundation from which to build on top of. The chosen team will:
- Select a small set of AI models representing the current state-of-the-art, profile the operation of these models on the latest commercial hardware, and report on the cost and existing performance bottlenecks.
- Update these reports continuously as the industry evolves and publish quarterly reports of their findings to the global R&D community, serving as an open, nimble, and scientifically grounded source of information.
Ultimately this work will help ensure that each of the ambitious technologies developed within the Programme are measured against the most up-to-date advances in the field.
Benchmarking activities are running from May 2025 through the remainder of the programme in Autumn 2027.